Clasificación de las Decisiones Judiciales con Inteligencia Artificial: Segunda Parte
Este post es parte de una serie. Antes de leer, consulte el Publicación anterior .
Convencidos de la utilidad de un clasificador de las decisiones judiciales en cuanto a su resultado, comenzamos a organizar los datos. El primer paso fue descargar las sentencias del STF y desarrollar un modelo relacional para estructurar la información. Básicamente, era necesario construir una colección y los campos en los que se fragmentaría cada juicio.
Para ello, se desarrolló un programa informático capaz de descargar y almacenar los datos separados por sentencia, clase, número y, especialmente, con la identificación del respectivo acta de sentencia. Como parece intuitivo, Esta es una fase que requiere una gran inversión En cuanto a la tecnología, combinado con la atención del equipo de juristas para separar las partes de la sentencia a consultar para la posterior clasificación de las decisiones.
Hemos separado lo esencial de una manera muy detallada y hemos mantenido cierta información en bruto para su posterior revisión. Dividimos el equipo en los responsables de la lectura de las actas de cada clase procesal, comenzando por los siguientes: mandamiento judicial, demanda, habeas corpus y recurso extraordinario. Decidimos no trabajar con otros procesos, ya que eran muy pequeños.
Mientras que las primeras clases tenían unos pocos miles de sentencias cada una, las apelaciones extraordinarias se evaluaron en un volumen mucho mayor. De hecho, su mayor volumen siempre ha sido un obstáculo para la investigación empírica sobre el control difuso de la constitucionalidad, ya que se necesita más organización para trabajar en las decisiones en decenas de miles de líneas. Realmente no es algo que un investigador pueda hacer simplemente .
Organizamos estos datos en una plataforma de anotaciones, de tal manera que, en conjunto, el equipo de juristas pudiera proponer un modelo inicial para clasificar los resultados de las sentencias. Después de mucha discusión sobre las opciones de construir un clasificador más complejo o más simple, surgió el siguiente modelo:
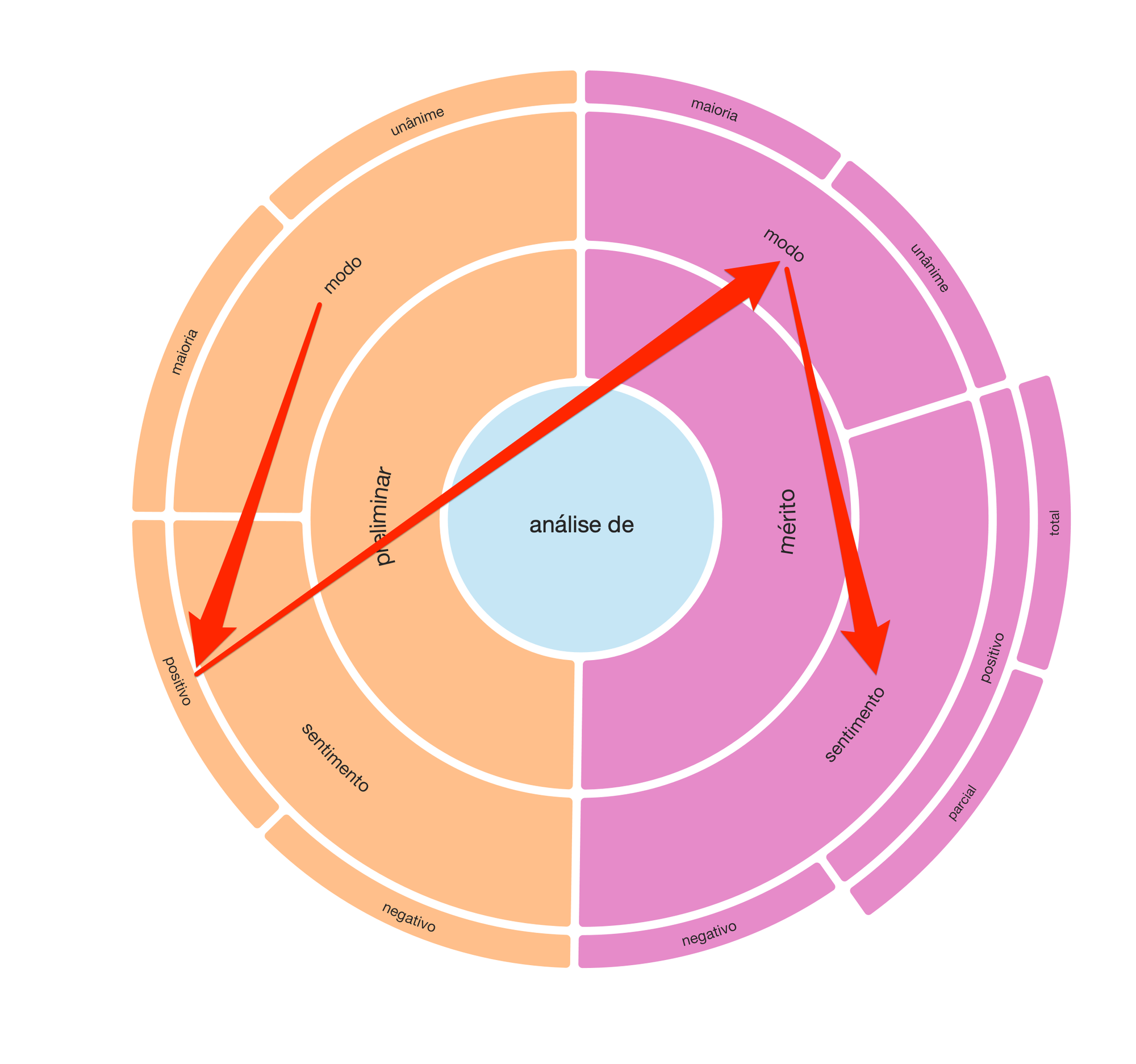
Por lo tanto, decidimos emitir un juicio preliminar (por mayoría o unanimidad) que, de ser positivo, llevaría a la evaluación de fondo. Asimismo, el juicio de fondo fue bipartito en sus modos (mayoría o unanimidad) y sus respectivos resultados: positivo y negativo. Por último, específicamente para el juicio de mérito positivo, también dividimos la valoración por el alcance del precepto: total o parcial.
A partir de esta secuencia de juicios, ilustrada en el radial, podríamos ampliar la muestra a las decenas de miles de juicios de una manera consistente.
Lo que faltaba era solo una plataforma de toma de notas que pudiera albergar este trabajo, permitiendo a los investigadores el acceso simultáneo a la colección. A continuación, transferimos la colección a una infraestructura en la nube dotada de esta capacidad e iniciamos la clasificación. Un ejemplo simplificado de cómo se estructuran los datos, tomando como ejemplo los writs of mandamus, es el siguiente:
Aunque se han omitido algunas partes de la tabla (lo que preserva la originalidad de la investigación hasta su publicación), ya es posible notar la estructura que establecimos para la anotación del modo (mayoría o unanimidad). A modo de ejemplo, en el caso de los recursos extraordinarios, clasificamos 3.972 sentencias como unánimes, con las siguientes variantes: unanimidad, unanimidad, unanimidad, acuerdo de votos y decisión uniforme.
Esto significa que, en este punto, Nuestra base de datos cuenta ahora con casi cuatro mil enlaces debidamente etiquetado. Son procesos reales, de los que conocemos varios atributos. La misma filosofía se aplica al vocabulario presente en la colección para clasificar el resultado (positivo o negativo) del juicio. La diferencia es que no solo hay cinco, sino cientos de variaciones de palabras que se utilizan para traducir el resultado de un juicio.
Como sabemos mucho sobre cada uno de estos procesos, se hace posible entrenar a una máquina para que, reconociendo un patrón, sugiera una etiqueta contemplando el modo (por ejemplo, unánime) y el resultado (por ejemplo, desfavorable) frente a un nuevo juicio que pueda dictarse. Así, enseñamos a la máquina a clasificar rápidamente miles de nuevas decisiones, basándonos en la curación llevada a cabo por nuestros investigadores.
El aprendizaje automático en sí mismo tampoco es una tarea trivial y será objeto de una nueva publicación. Hasta ahora, solo nos hemos ocupado de la preparación de los datos , que es un paso esencial y que a menudo se pasa por alto. Sin datos debidamente organizados, no es posible desarrollar soluciones de inteligencia artificial.