inteligencia artificial
La CEPEJ (Comisión Europea para la Eficiencia de la Justicia) es una de las principales fuentes para los amantes del derecho comparado. En su última sesión plenaria (12/08/2021), se aprobó un Plan de Acción Cuatrienal, con el objetivo de adoptar nuevas tecnologías para la mejora de la Justicia.
El plan pretende conciliar, con la ayuda de la tecnología, la eficacia de la prestación con la calidad de los servicios públicos jurisdiccionales. Los ejes que sustentan esta estrategia son la transparencia, la colaboración, la valoración de las personas, la accesibilidad, la racionalidad, la responsabilidad y la capacidad de respuesta.
Al mismo tiempo, en la misma ocasión, la CEPEJ revisó su planificación para la promoción del uso ético de la inteligencia artificial (IA) por parte del Poder Judicial. El trabajo actualmente revisado comenzó en 2018, cuando se establecieron cinco puntos clave para adoptar soluciones de IA : respeto de los derechos fundamentales; la no discriminación; calidad y seguridad de los datos; transparencia, imparcialidad y equidad; así como la independencia del usuario.
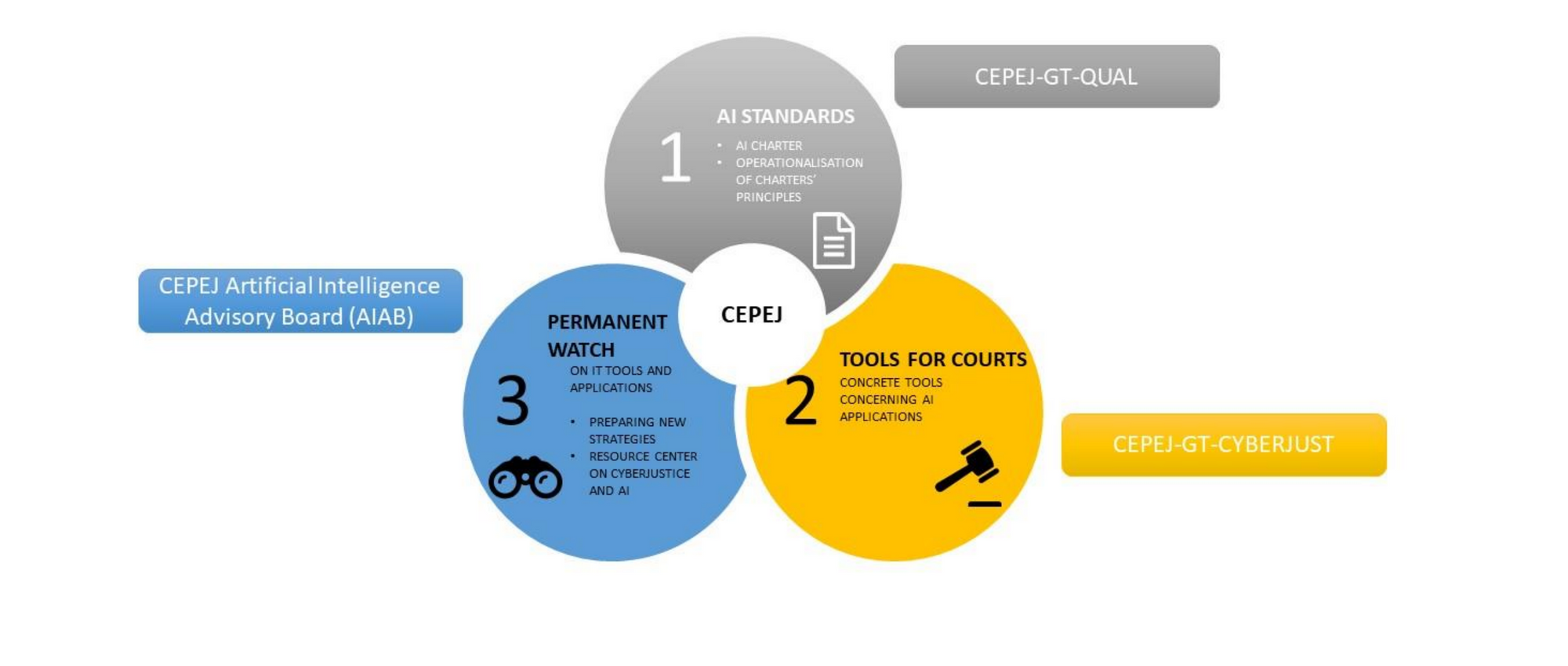
Desde el principio, la CEPEJ ha demostrado que es consciente de que no existe una solución mágica al asunto, sobre todo teniendo en cuenta su espíritu pionero en tratar de establecer las condiciones para que la IA avance respetando los derechos humanos. Dos años más tarde, el mismo grupo de trabajo inicial se propuso evaluar la viabilidad de esta misión, habiendo presentado su informe en 2020.
A mediados de 2021 se presentó la primera versión de la planificación para la certificación de soluciones de IA. Sin embargo, teniendo en cuenta los debates que habían tenido lugar y la dificultad de crear una solución que respetara la visión de varios países, la conclusión de los trabajos se aplazó hasta la sesión plenaria de fin de año.
El objetivo de esta iniciativa (impulsada por el Consejo de Europa), a pesar de su etapa inicial, es regular las soluciones de IA de alto riesgo. Dado que hay muchos países implicados, es natural que Europa no avance tan rápidamente en este punto. A modo de ejemplo, Brasil ya cuenta con una regulación de la materia, que incluye lineamientos establecidos por el CNJ. En este punto podemos decir que estamos más avanzados que Europa.
IA en Folha de São Paulo: ¿artículo o publicación?
Comentario a los artículos de Folha de São Paulo sobre aplicaciones de la inteligencia artificial en el mundo del Derecho.
Folha de São Paulo publicó recientemente una serie de artículos sobre inteligencia artificial. A pesar del inusual anuncio, el artículo no fue promocionado como un publirreportaje. Este es el titular del artículo del 20/02/20:
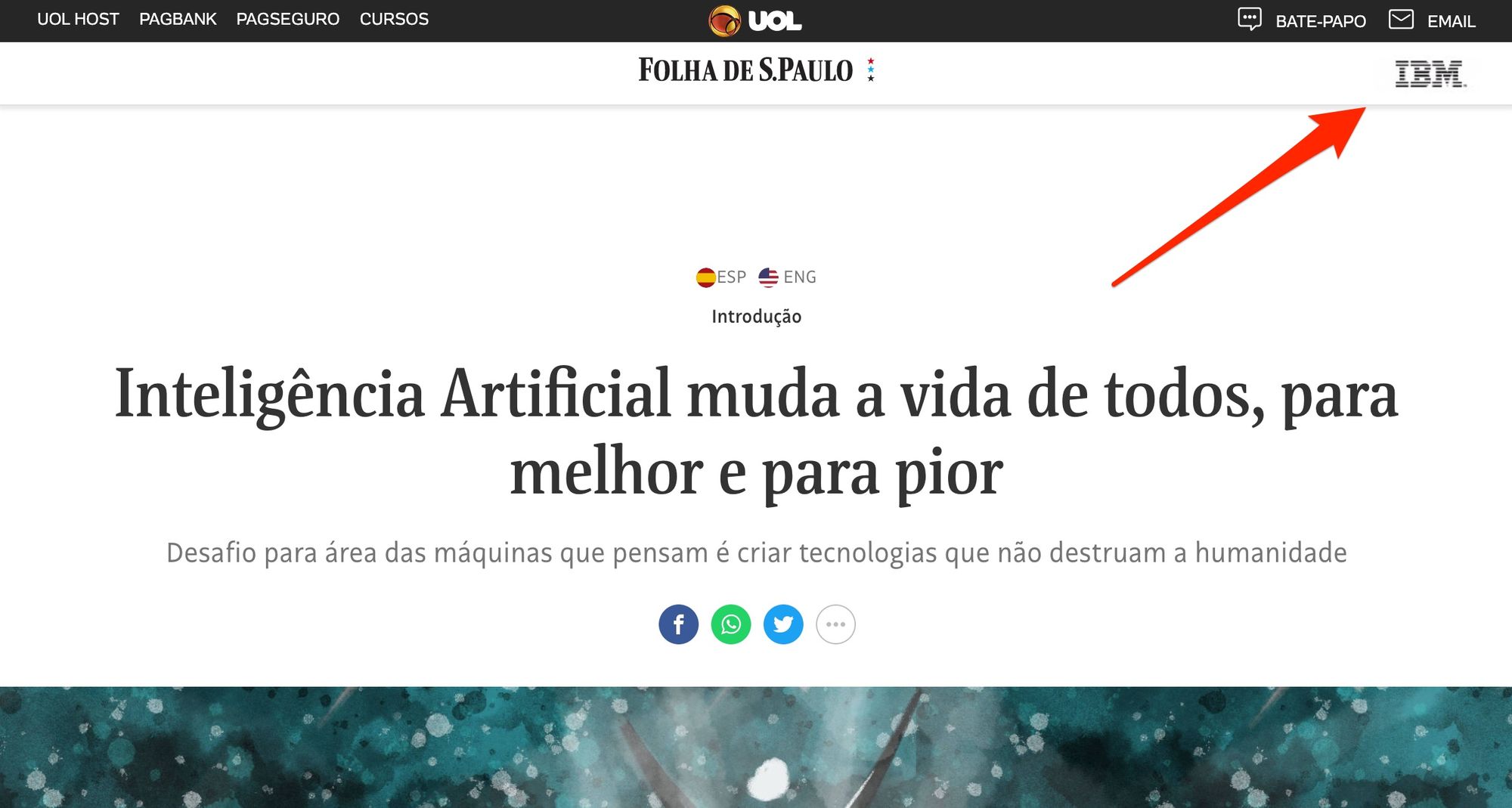
Y este es su pie de página:
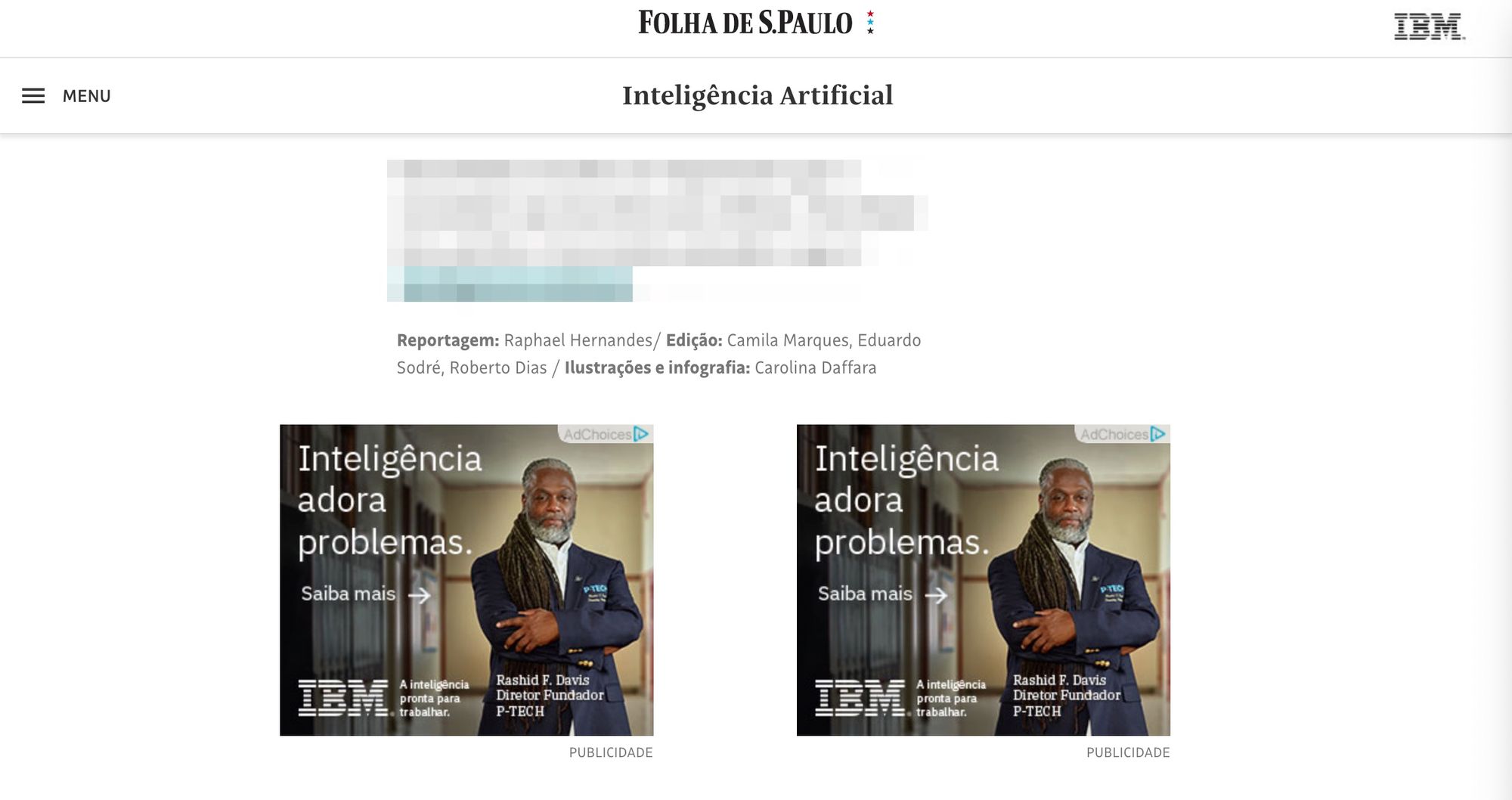
Es decir, puede que ni siquiera sea un publirreportaje, pero seguro que es una columna patrocinada. Esto demuestra que Folha se dedica a una actividad educativa (encomiable), lo que no nos exime de considerar patrocinadores cuando encontramos alguna noticia que nos interesa especialmente.
Muy bien. En este contexto, Folha también publicó el 03/10/20: "La inteligencia artificial actúa como juez, cambia la estrategia de los abogados y promueve la pasantía".

Como no sé si mi comentario estaría autorizado en el sistema de Folha, dejé aquí mi guión de lectura para el artículo. Espero que, con estas advertencias, el artículo sea más informativo sobre el uso de la Inteligencia Artificial (IA) en el Derecho:
- Folha: "Según la versión más reciente de "Justicia en Números" (...), 108,3 millones de casos comenzaron en versión digital entre 2008 y 2018. Yo: Esto no es muy relevante para la IA, ya que lo que se transfirió a la plataforma digital fue el procesamiento. Los registros siguen siendo archivos PDF normales, que no proporcionan fácilmente el tipo de datos que consumen los sistemas inteligentes.
- Folha: "Ilustración de Diana, nombre dado al programa de inteligencia artificial del bufete de abogados Lee, Brock e Camargo Advogados". Yo: ¿En serio?
Folha: "Macêdo utiliza a diario el sistema, llamado Elis (en el Poder Judicial de Pernambuco)". Yo: Está bien que nombrar las cosas sea divertido. Pero, ¿necesitamos otro robot en 2020?
Folha: "En el propio texto de la decisión, se dice que fue Elis quien lo hizo, para permitir transparencia en el proceso, para que se sepa qué se está utilizando". Yo: ¿Pones en la decisión lo que se hizo en Word o en máquina de escribir?
Folha: "Según Juliana Neiva, secretaria de Tecnologías de la Información y las Comunicaciones del tribunal, el desarrollo de la IA no tuvo ningún costo para el tribunal, ya que fue desarrollado por los propios servidores del organismo". Yo: ¿Los servidores son de coste cero?
Folha: "El STJ quiere ir más allá en el uso de la tecnología e informa que ya está en marcha el proyecto Sócrates 2, en el que la idea es avanzar para que la IA pronto proporcione a los jueces todos los elementos necesarios para el juicio de las causas, como la descripción de las tesis de las partes y las principales decisiones ya tomadas por el tribunal en relación con el tema del caso". Yo: ¿Es la IA la mejor (o la única) forma de hacer esto?
Folha: "Para hacer frente a este problema, el bufete de abogados Lee, Brock e Camargo Advogados (LBCA) desarrolló una aplicación vinculada a un sistema de IA. El mecanismo permite plantear, luego de conocer quiénes son los deponentes de la parte contraria, todo lo que estos testigos ya han dicho en otros procesos, dice Solano de Camargo, socio fundador de LBCA. Yo: ¿Alguien cree que necesita IA para eso? ¿Es este realmente un problema central para una firma de litigios masivos? ¿No es importante saber lo que el testigo dirá sobre los hechos de ese caso en particular?
Folha: "El sistema de IA de la empresa se llamó Diana y ya consumió inversiones por R$ 3 millones en los últimos años, dice Camargo. El costo incluye la implementación de un laboratorio interno de tecnología que cuenta con 41 miembros". Yo: Con 41 miembros, ni siquiera necesitas inteligencia artificial. El objetivo de la tecnología es dar más productividad para que puedas tener equipos pequeños.
Folha: "Ejemplos de uso: El bufete de abogados Lee, Brock e Camargo Advogados (LBCA), en São Paulo, desarrolló un sistema de IA y una aplicación conectada a él. Los abogados del bufete pueden abrir la aplicación durante las audiencias y utilizar el análisis del software para identificar, por ejemplo, las contradicciones de un testigo mientras habla con el juez". Yo: Necesito escribir un post sobre esto.
Folha de São Paulo es un periódico muy importante y, en mi opinión, debería ser más selectivo en sus publicaciones. Es natural que un periódico tenga anunciantes. Sin embargo, no es normal desinformar de esta manera. Sería muy chévere que Folha le diera seguimiento al artículo de una manera menos capturada. O bien dejaría más claro quién es el anunciante, de lo contrario se convertiría en una página más en internet.
Finalmente Foro Británico de Tecnología Legal , celebrado en Londres esta semana, se trataron varios temas relacionados con la inteligencia artificial aplicada al derecho. El blog Abogado Artificial estuvo allí y publicó una interesante reflexión sobre una nueva ola de opiniones sobre la inteligencia artificial, a la que llamó "Post-Hype AI Hype".
Para aquellos que no están familiarizados, El hype es algo exagerado y con una connotación negativa . Cualquier tema que esté dando que hablar, que esté de moda, pero que al mismo tiempo no tenga un fundamento probado, está promocionado. En el contexto de la tecnología, algo que está en auge trae consigo un gran temor de que el estado actual de la tecnología no sea suficiente para resolver los problemas que se propone enfrentar.
El movimiento actual, diagnosticado esta semana, sostiene que el ciclo de expectativas exacerbadas sobre El potencial de la inteligencia artificial está llegando a su fin . En lugar de hablar de un futuro lejano, este movimiento tiene como objetivo reflexionar sobre aplicaciones prácticas e inmediatas, que generalmente requieren tecnologías que ya están establecidas. En otras palabras, se ha formado un nuevo ciclo en el sector contra la inteligencia artificial, pero también es una especie de exageración.
Básicamente Ahora tenemos un nuevo bombo que ocupa el lugar del otro . Ninguno de ellos fue creado deliberadamente, porque estaban compuestos por una suma de voces que realmente creían en lo que prometían como solución a todos los problemas. Hoy, recauchutado, el bombo se organiza para huir de la terminología celebrada hasta entonces, pero esto no es algo que venga sin ninguna dificultad. Al fin y al cabo, aunque de forma imprecisa, la inteligencia artificial ya es un término incorporado al vocabulario actual. En cualquier caso, esto ha hecho posible la comunicación hasta ahora.
Debatir temas relacionados hablando de machine learning, procesamiento del lenguaje natural, clasificación automática de decisiones, entre otros términos, es algo que requeriría mucha más energía. Ciertamente, esto no beneficia a las empresas que utilizan la jerga sólo como marketing, sin ningún compromiso de incorporar la tecnología que anuncian en sus productos.
Parece que el término inteligencia artificial ha perdido su frescura . Al mismo tiempo, y no por casualidad, algunas de sus promesas simplemente no se cumplieron para el mercado legal. Estamos viviendo una resaca similar a la que ha pasado recientemente la medicina, ya que la inteligencia artificial no ha descubierto la "cura para el cáncer". Y todavía no tenemos la "cura para los procesos".
De ciclo en ciclo, el hype se revela como la forma misma de ser de las comunidades profesionales con un control limitado sobre lo que debe discutirse y entenderse en profundidad. Una vez instalado, no se disuelve fácilmente, siendo sucedido por una nueva promesa que tampoco se cumplirá. Esta cadena de promesas y frustraciones es propia de sectores que consumen tecnología, sin tener las herramientas para entenderla a cabalidad.
Así La exageración es una consecuencia de nuestra propia falta de dominio técnico , de nuestra consecuente superficialidad en este campo. Los ingredientes adicionales son el interés de las personas por alimentar el hype, por ejemplo, un conferenciante que reafirme sus supuestos conocimientos o empresas que vendan el hype, ya que trabajan en la lógica de la comunicación inmediata y facilitada.
Los elementos finales son las palabras inteligencia y artificial, que transmiten un sentido muy equívoco de lo que realmente son cuando se usan juntas. Sería mejor que esta tecnología no tuviera su contenido inducido por palabras que creemos entender, porque forman parte de nuestro lenguaje en otros contextos.
Aunque un abogado entiende perfectamente los desafíos legales de su trabajo diario, difícilmente entendería todo lo que rodea tecnológicamente a los productos disponibles en su mercado. Si le dijeran que la solución a sus problemas sería usar la inteligencia artificial, lo más probable es que lo engañaran. Después de todo, puede imaginar erróneamente de qué se trata. Por el contrario, el mismo abogado no se vería afectado si se le aconsejara utilizar una solución de "banco de gráficos".
Los nombres técnicos no comunican y tampoco venden. En este sentido, la inteligencia artificial es víctima de esta desafortunada coincidencia. Para escapar del nuevo bombo, será necesario que nuestra comunidad se dedique a entender qué es realmente la inteligencia artificial y cuáles son sus posibilidades reales. De lo contrario, continuaremos en la sucesión de bombos y platillos , que alienan más de lo que informan.
Este post es parte de una serie. Antes de leer, consulte el Publicación anterior .
Convencidos de la utilidad de un clasificador de las decisiones judiciales en cuanto a su resultado, comenzamos a organizar los datos. El primer paso fue descargar las sentencias del STF y desarrollar un modelo relacional para estructurar la información. Básicamente, era necesario construir una colección y los campos en los que se fragmentaría cada juicio.
Para ello, se desarrolló un programa informático capaz de descargar y almacenar los datos separados por sentencia, clase, número y, especialmente, con la identificación del respectivo acta de sentencia. Como parece intuitivo, Esta es una fase que requiere una gran inversión En cuanto a la tecnología, combinado con la atención del equipo de juristas para separar las partes de la sentencia a consultar para la posterior clasificación de las decisiones.
Hemos separado lo esencial de una manera muy detallada y hemos mantenido cierta información en bruto para su posterior revisión. Dividimos el equipo en los responsables de la lectura de las actas de cada clase procesal, comenzando por los siguientes: mandamiento judicial, demanda, habeas corpus y recurso extraordinario. Decidimos no trabajar con otros procesos, ya que eran muy pequeños.
Mientras que las primeras clases tenían unos pocos miles de sentencias cada una, las apelaciones extraordinarias se evaluaron en un volumen mucho mayor. De hecho, su mayor volumen siempre ha sido un obstáculo para la investigación empírica sobre el control difuso de la constitucionalidad, ya que se necesita más organización para trabajar en las decisiones en decenas de miles de líneas. Realmente no es algo que un investigador pueda hacer simplemente .
Organizamos estos datos en una plataforma de anotaciones, de tal manera que, en conjunto, el equipo de juristas pudiera proponer un modelo inicial para clasificar los resultados de las sentencias. Después de mucha discusión sobre las opciones de construir un clasificador más complejo o más simple, surgió el siguiente modelo:
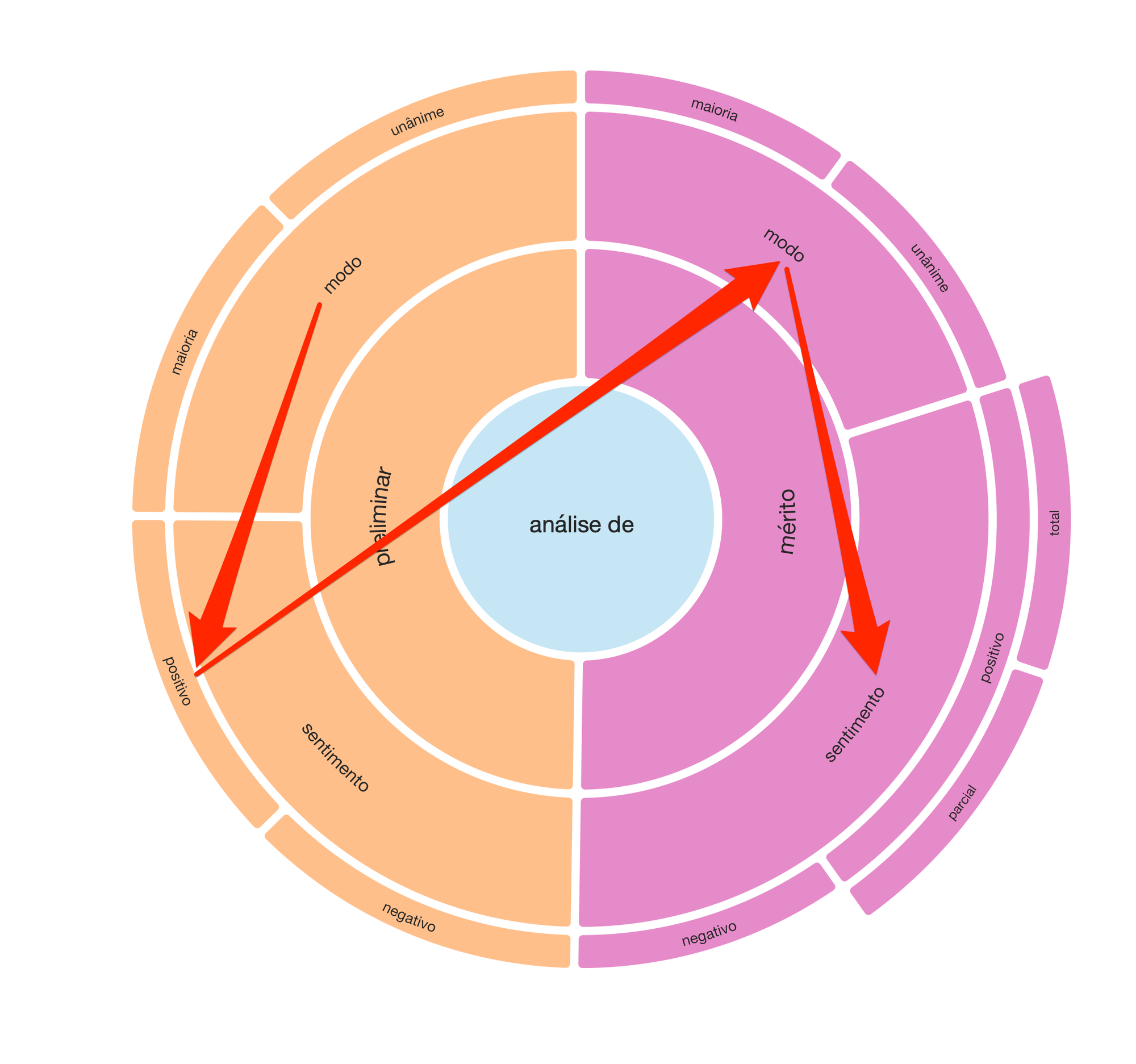
Por lo tanto, decidimos emitir un juicio preliminar (por mayoría o unanimidad) que, de ser positivo, llevaría a la evaluación de fondo. Asimismo, el juicio de fondo fue bipartito en sus modos (mayoría o unanimidad) y sus respectivos resultados: positivo y negativo. Por último, específicamente para el juicio de mérito positivo, también dividimos la valoración por el alcance del precepto: total o parcial.
A partir de esta secuencia de juicios, ilustrada en el radial, podríamos ampliar la muestra a las decenas de miles de juicios de una manera consistente.
Lo que faltaba era solo una plataforma de toma de notas que pudiera albergar este trabajo, permitiendo a los investigadores el acceso simultáneo a la colección. A continuación, transferimos la colección a una infraestructura en la nube dotada de esta capacidad e iniciamos la clasificación. Un ejemplo simplificado de cómo se estructuran los datos, tomando como ejemplo los writs of mandamus, es el siguiente:
Aunque se han omitido algunas partes de la tabla (lo que preserva la originalidad de la investigación hasta su publicación), ya es posible notar la estructura que establecimos para la anotación del modo (mayoría o unanimidad). A modo de ejemplo, en el caso de los recursos extraordinarios, clasificamos 3.972 sentencias como unánimes, con las siguientes variantes: unanimidad, unanimidad, unanimidad, acuerdo de votos y decisión uniforme.
Esto significa que, en este punto, Nuestra base de datos cuenta ahora con casi cuatro mil enlaces debidamente etiquetado. Son procesos reales, de los que conocemos varios atributos. La misma filosofía se aplica al vocabulario presente en la colección para clasificar el resultado (positivo o negativo) del juicio. La diferencia es que no solo hay cinco, sino cientos de variaciones de palabras que se utilizan para traducir el resultado de un juicio.
Como sabemos mucho sobre cada uno de estos procesos, se hace posible entrenar a una máquina para que, reconociendo un patrón, sugiera una etiqueta contemplando el modo (por ejemplo, unánime) y el resultado (por ejemplo, desfavorable) frente a un nuevo juicio que pueda dictarse. Así, enseñamos a la máquina a clasificar rápidamente miles de nuevas decisiones, basándonos en la curación llevada a cabo por nuestros investigadores.
El aprendizaje automático en sí mismo tampoco es una tarea trivial y será objeto de una nueva publicación. Hasta ahora, solo nos hemos ocupado de la preparación de los datos , que es un paso esencial y que a menudo se pasa por alto. Sin datos debidamente organizados, no es posible desarrollar soluciones de inteligencia artificial.
Este post es parte de una serie. Antes de leer, consulte el Publicación anterior .
Convencidos de la utilidad de un clasificador de las decisiones judiciales en cuanto a su resultado, comenzamos a organizar los datos. El primer paso fue descargar las sentencias del STF y desarrollar un modelo relacional para estructurar la información. Básicamente, era necesario construir una colección y los campos en los que se fragmentaría cada juicio.
Para ello, se desarrolló un programa informático capaz de descargar y almacenar los datos separados por sentencia, clase, número y, especialmente, con la identificación del respectivo acta de sentencia. Como parece intuitivo, Esta es una fase que requiere una gran inversión En cuanto a la tecnología, combinado con la atención del equipo de juristas para separar las partes de la sentencia a consultar para la posterior clasificación de las decisiones.
Hemos separado lo esencial de una manera muy detallada y hemos mantenido cierta información en bruto para su posterior revisión. Dividimos el equipo en los responsables de la lectura de las actas de cada clase procesal, comenzando por los siguientes: mandamiento judicial, demanda, habeas corpus y recurso extraordinario. Decidimos no trabajar con otros procesos, ya que eran muy pequeños.
Mientras que las primeras clases tenían unos pocos miles de sentencias cada una, las apelaciones extraordinarias se evaluaron en un volumen mucho mayor. De hecho, su mayor volumen siempre ha sido un obstáculo para la investigación empírica sobre el control difuso de la constitucionalidad, ya que se necesita más organización para trabajar en las decisiones en decenas de miles de líneas. Realmente no es algo que un investigador pueda hacer simplemente .
Organizamos estos datos en una plataforma de anotaciones, de tal manera que, en conjunto, el equipo de juristas pudiera proponer un modelo inicial para clasificar los resultados de las sentencias. Después de mucha discusión sobre las opciones de construir un clasificador más complejo o más simple, surgió el siguiente modelo:
Por lo tanto, decidimos emitir un juicio preliminar (por mayoría o unanimidad) que, de ser positivo, llevaría a la evaluación de fondo. Asimismo, el juicio de fondo fue bipartito en sus modos (mayoría o unanimidad) y sus respectivos resultados: positivo y negativo. Por último, específicamente para el juicio de mérito positivo, también dividimos la valoración por el alcance del precepto: total o parcial.
A partir de esta secuencia de juicios, ilustrada en el radial, podríamos ampliar la muestra a las decenas de miles de juicios de una manera consistente.
Lo que faltaba era solo una plataforma de toma de notas que pudiera albergar este trabajo, permitiendo a los investigadores el acceso simultáneo a la colección. A continuación, transferimos la colección a una infraestructura en la nube dotada de esta capacidad e iniciamos la clasificación. Un ejemplo simplificado de cómo se estructuran los datos, tomando como ejemplo los writs of mandamus, es el siguiente:
Aunque se han omitido algunas partes de la tabla (lo que preserva la originalidad de la investigación hasta su publicación), ya es posible notar la estructura que establecimos para la anotación del modo (mayoría o unanimidad). A modo de ejemplo, en el caso de los recursos extraordinarios, clasificamos 3.972 sentencias como unánimes, con las siguientes variantes: unanimidad, unanimidad, unanimidad, acuerdo de votos y decisión uniforme.
Esto significa que, en este punto, Nuestra base de datos cuenta ahora con casi cuatro mil enlaces debidamente etiquetado. Son procesos reales, de los que conocemos varios atributos. La misma filosofía se aplica al vocabulario presente en la colección para clasificar el resultado (positivo o negativo) del juicio. La diferencia es que no solo hay cinco, sino cientos de variaciones de palabras que se utilizan para traducir el resultado de un juicio.
Como sabemos mucho sobre cada uno de estos procesos, se hace posible entrenar a una máquina para que, reconociendo un patrón, sugiera una etiqueta contemplando el modo (por ejemplo, unánime) y el resultado (por ejemplo, desfavorable) frente a un nuevo juicio que pueda dictarse. Así, enseñamos a la máquina a clasificar rápidamente miles de nuevas decisiones, basándonos en la curación llevada a cabo por nuestros investigadores.
El aprendizaje automático en sí mismo tampoco es una tarea trivial y será objeto de una nueva publicación. Hasta ahora, solo nos hemos ocupado de la preparación de los datos , que es un paso esencial y que a menudo se pasa por alto. Sin datos debidamente organizados, no es posible desarrollar soluciones de inteligencia artificial.
Los profesionales del derecho consumen varios tipos de información jurídica, dos de los cuales son los principales: el derecho y la jurisprudencia. La ley es una norma abstracta, es decir, no se ha aplicado a un caso concreto. La jurisprudencia, por su parte, es una norma concreta, hecha para resolver un caso sometido al Poder Judicial.
Aunque es relativamente fácil conocer las leyes, ya que se publican en repositorios oficiales, es mucho más complejo conocer la jurisprudencia. El repositorio legislativo más utilizado es el de la Meseta e ilustra bien cómo se organizan y consumen en Brasil las diversas formas de legislación federal. Por el contrario, Existen varios tribunales y cada uno se encarga de publicar su propia jurisprudencia .
En general, los tribunales tratan estos datos como documentos en lenguaje natural, con una capa adicional relativamente limitada de metadatos.
Así, existen pocos filtros para acceder a esta información, por ejemplo: la fecha de la sentencia, el nombre del juez, el órgano al que pertenece este juez, el nombre y cargo de cada parte en el proceso, etc. Sin embargo, no encontramos ningún repositorio público organizado en torno a la dimensión del resultado del juicio, ya sea favorable o desfavorable a su resultado.
Consideremos el siguiente caso de uso:
Es posible imaginar que un abogado de un banco realiza una investigación sobre la jurisprudencia en un determinado tribunal para evaluar las posibilidades de éxito de una nueva demanda.
Como la base de juicio del STF está indexada, puede, con cierta facilidad, encontrar casos concretos que trataron un determinado tema. Sin embargo, el abogado tiene mucha dificultad para encontrar, dentro de este tema, cuáles fueron los casos ganados por los bancos y en los que los mismos bancos fueron derrotados.
La utilidad de desarrollar una solución que comprenda cuáles son los casos favorables y desfavorables radica en posibilitar una consulta agregada también por esta dimensión, refiriéndose al resultado del juicio. Al fin y al cabo, la consulta profesional casi siempre tiene una vertiente interesada, de tal manera que conocer el desenlace del caso es una información muy importante para la vida práctica de los profesionales del derecho.
En las próximas semanas, publicaremos aquí el viaje de varios de los investigadores de DireitoTec, dedicados a mapear decenas de miles de sentencias STF. Esto permitirá crear una base para la formación en inteligencia artificial de tal manera que es posible clasificar automáticamente el resultado de una sentencia. ¿Qué dices? ¿Suena prometedor?
Este post es parte de una serie. Véase el Publicación siguiente .
Los profesionales del derecho consumen varios tipos de información jurídica, dos de los cuales son los principales: el derecho y la jurisprudencia. La ley es una norma abstracta, es decir, no se ha aplicado a un caso concreto. La jurisprudencia, por su parte, es una norma concreta, hecha para resolver un caso sometido al Poder Judicial.
Aunque es relativamente fácil conocer las leyes, ya que se publican en repositorios oficiales, es mucho más complejo conocer la jurisprudencia. El repositorio legislativo más utilizado es el de la Meseta e ilustra bien cómo se organizan y consumen en Brasil las diversas formas de legislación federal. Por el contrario, Existen varios tribunales y cada uno se encarga de publicar su propia jurisprudencia .
En general, los tribunales tratan estos datos como documentos en lenguaje natural, con una capa adicional relativamente limitada de metadatos.
Así, existen pocos filtros para acceder a esta información, por ejemplo: la fecha de la sentencia, el nombre del juez, el órgano al que pertenece este juez, el nombre y cargo de cada parte en el proceso, etc. Sin embargo, no encontramos ningún repositorio público organizado en torno a la dimensión del resultado del juicio, ya sea favorable o desfavorable a su resultado.
Consideremos el siguiente caso de uso:
Es posible imaginar que un abogado de un banco realiza una investigación sobre la jurisprudencia en un determinado tribunal para evaluar las posibilidades de éxito de una nueva demanda.
Como la base de juicio del STF está indexada, puede, con cierta facilidad, encontrar casos concretos que trataron un determinado tema. Sin embargo, el abogado tiene mucha dificultad para encontrar, dentro de este tema, cuáles fueron los casos ganados por los bancos y en los que los mismos bancos fueron derrotados.
La utilidad de desarrollar una solución que comprenda cuáles son los casos favorables y desfavorables radica en posibilitar una consulta agregada también por esta dimensión, refiriéndose al resultado del juicio. Al fin y al cabo, la consulta profesional casi siempre tiene una vertiente interesada, de tal manera que conocer el desenlace del caso es una información muy importante para la vida práctica de los profesionales del derecho.
En las próximas semanas, publicaremos aquí el viaje de varios de los investigadores de DireitoTec, dedicados a mapear decenas de miles de sentencias STF. Esto permitirá crear una base para la formación en inteligencia artificial de tal manera que es posible clasificar automáticamente el resultado de una sentencia. ¿Qué dices? ¿Suena prometedor?
Este post es parte de una serie. Véase el Publicación siguiente .
El presidente de los Estados Unidos, Donald Trump, firmó recientemente (11/02/19) un " ORDEN EJECUTIVA para, en estas palabras, "mantener el liderazgo" del país en el campo de la inteligencia artificial. Si bien es innegable que EE.UU. juega un papel muy importante en este ámbito, no es tan sencillo posicionarse como líder. De hecho, la propia preocupación por mantener una supuesta ventaja demuestra que hay al menos una amenaza seria en esta carrera por la IA, en la que China ha estado destacando mucho.
Más que una promesa: años de presupuesto
Para llevar a cabo esta misión se nombró un Comité vinculado al Consejo Nacional de Ciencia y Tecnología (NSTC, por sus siglas en inglés), de tal manera que se espera una amplia coordinación del gobierno federal estadounidense, incluyendo a todas sus agencias. Se anima a los directores de estas agencias, a partir de ahora, a priorizar las inversiones en IA, haciendo que sus propuestas presupuestarias contemplen inversiones en la zona y, especialmente, durante los próximos años.
Es decir, hay una preocupación por aportar fondos para la iniciativa y el programa reconoce que el desarrollo de la IA es algo que, además de dinero, también consume mucho tiempo. Y esto convive con un sentido de urgencia, ya que la ley establece un plazo de 90 días para que cada organismo indique cómo piensa comprometer su presupuesto anual para alcanzar los objetivos marcados por la norma.
Principios y objetivos estratégicos
El acto de Trump se guía por cinco principios: promoción de la ciencia, competitividad económica y seguridad nacional; reducir las barreras a los experimentos de IA con el fin de ampliar su uso; educar a los ciudadanos para enfrentar la revolución económica provocada por la tecnología; garantía de las libertades civiles y de la intimidad; así como mantener la posición estratégica de EE.UU. en el mercado mundial de IA.
Parece un buen resumen de todo lo que promete esta tecnología en cuanto a avances y también riesgos derivados de ella. Así, al mismo tiempo que Trump refuerza la importancia estratégica de ser protagonista en la exportación de IA, delimita que este activo debe ser protegido para que no caiga en manos de adversarios comerciales y, especialmente, enemigos. Trump también está comprometido a mantener la empleabilidad de los ciudadanos estadounidenses, en vista de la anunciada extinción [en mi opinión, prematuramente] de varias profesiones.
Los principios enumerados deben estar encaminados, en el ámbito del gobierno federal, a alcanzar seis objetivos estratégicos: convertir la investigación en IA en innovación aplicada a la práctica; aumentar el suministro de datos y ampliar el acceso a computadoras especializadas; preservar la seguridad y la privacidad, incluso ante la expansión de los usos de la IA; reducir la vulnerabilidad de los sistemas a ataques maliciosos; garantizar que los empleados públicos y privados puedan utilizar las nuevas tecnologías; y, finalmente, mantener el liderazgo de Estados Unidos en la zona.
El cronograma y los plazos
Además de establecer competencias, principios y objetivos estratégicos, la "orden ejecutiva" crea un cronograma para que se logren. El primer paso es la mejora en el suministro de datos por parte del gobierno federal, que se reconoce como un cuello de botella para el desarrollo de la IA.
Se prevé una convocatoria pública para, en un plazo de 90 días, identificar las demandas de la sociedad civil y la academia en relación a qué servicios se deben priorizar. Dentro de los 120 días posteriores a la publicación de la ley, con el apoyo del Ministerio de Planificación (OMB), el Comité Federal de Inteligencia Artificial (Comité Selecto) debe actualizar los lineamientos para la implementación de repositorios de datos y software, con el objetivo de mejorar la recuperación y el uso de la información.
Además de estas predicciones, la "orden ejecutiva" crea una serie de hitos urgentes para que el ciclo sea exitoso, comenzando con las demandas de los científicos de datos y cerrando con el cumplimiento de las mismas. Es decir, se trata de una planificación guiada por el uso y propósito que la sociedad quiere dar a los datos. El gobierno estadounidense no dice qué se debe hacer, llamándose solo el deber de organizar los datos, para que no haya filtraciones o violaciones de la privacidad.
Mi opinión: Carrera contra China
En mi opinión, la nueva ley de Trump es muy correcta y revela el verdadero choque de dos poderes. China es el líder en la recopilación de información (incluso cuestionable) y está avanzando rápidamente con su capacidad de procesamiento. Estados Unidos, por otro lado, puede incluso ser visto como un líder en la investigación de IA, pero depende de más datos para seguir luchando. Por lo tanto, la ley reorganiza las bases de la estructura de datos públicos estadounidense. Al fin y al cabo, sin datos es imposible avanzar en la ciencia de datos.
Aparentemente, cuando se trata de IA, a juzgar por los plazos e hitos descritos en el estándar estadounidense, el tiempo también es dinero. De hecho, mucho dinero. Prueba de ello es que EEUU está rehaciendo los cimientos, y no una mera renovación del techo.